Command line news headlines
Try it: npm install get-headlines -g (or without -g global flag)
Most projects I build come from a question, or a few. While part of the excuse of doing this project was to get more familiar with working with node and scraping data, I also wanted to help answer these questions:
- What tools can we build to make people more aware of the world around them?
- What info would be helpful to give a reader to fill in their gaps of awareness?
- What info exists already that we can use?
Ask, then build
I ended up focusing on local news for the following reasons: If an individual is to look at major news sites, for example BBC or the Globe and Mail, their top headlines are usually the same major international stories. There is little to glean about an actual geographical region and it’s pulse unless we start to look at what’s being written in subsets (local) news headlines.
While building this tool I also became aware of how information (stories) trickle up to bigger publications. Watching stories pick up steam attention-wise was a good part of the fun.
The command line tool in this project is part of a larger project I’m working on to take the pain out of accessing a wide variety of news headlines from around the world. The biggest pain if someone were to try do this now is figure out the DOM’s scraping path of each local news site. You can see I’ve had to manually find the best scraping path for each headline, which wasn’t too much fun.
Building a database for scraping
Design-wise, I’ve made it so that users can add additional arguments to specify if they want news from a specific city, province, state, or country. When you type in get-headlines canada, the scraper runs and grabs all the headlines I’ve specified it to get. For now I have it set to purposefully only grab the most recent headline of each website.
In their newer versions, Firefox does make it much easier to find the correct DOM path to get to an element. Once your FF inspector is open you can right click on an element in the inspector window and copy its path.
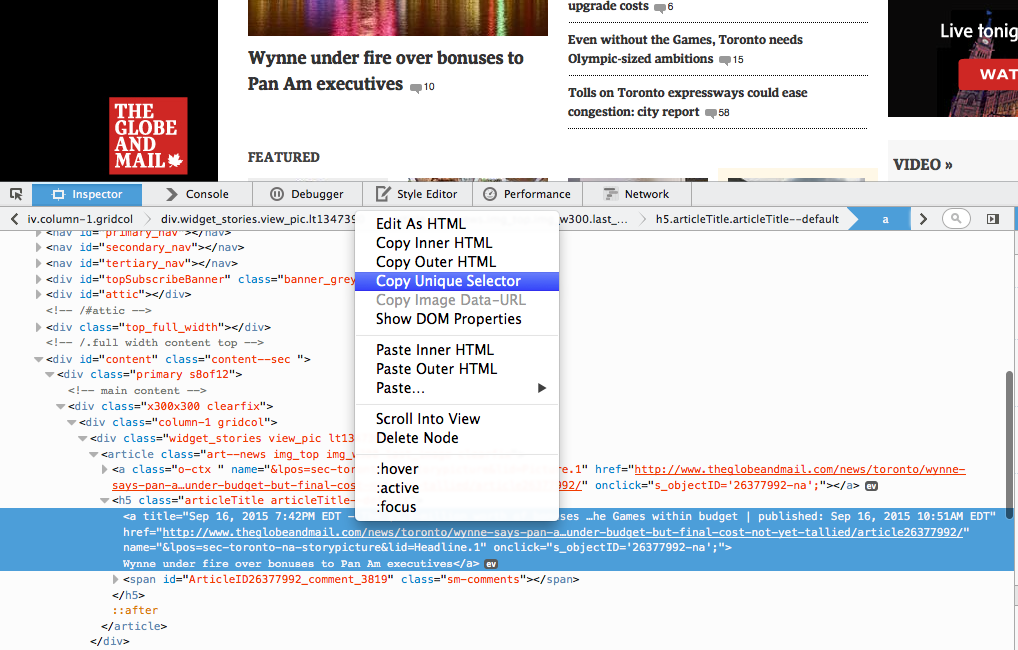
Anecdotally, there’s a wide range of ways we could get headlines outside of scraping. Many sites do have half-decent RSS feeds, and some (too few), have public API’s for their stories.
You can download the get-headlines command line tool with npm install get-headlines -g, or without -g if you don’t want it installed globally.
Right now there are 25 different local news sites that can be queried via command line. One difficulty going forward will be monitoring for when websites change their URL paths or site design, so the current scraper paths I have will no longer work. Adding a testing system would be a good way to get my attention that I need to update a site’s URL path or query path. [Since this post has been written Firefox has a much better built-in DOM path selector built into its developer tools. This saves a lot of time when updating broken DOM paths.]
What will the information be good for?
With all this local data you could…
- Interactive map to help people get a sense of what’s happening elsewhere
- Use it as a starting point for headline archival